Demo for WES data from a cancer patient¶
: ex: set ft=markdown ;:<<’```shell’ #
NOTE: this demo has not yet been updated for version 1.0 of HATCHet which includes variable-width binning, phasing, and locality-aware clustering.
The following HATCHet’s demo represents a guided example starting from WES (whole-exome sequencing) data from 2 samples of the same patient. WES data are an interesting case to consider as they are typically characterize by a larger variance, especially for RDR. For simplicity, the demo starts from a BB file demo-wes.bb (included in this demo at examples/demo-WES/) which contains the RDR and BAF of every genomic bin and, therefore, we assume that the preliminary steps (i.e. count-reads, count-alleles, and combine-counts) have already been executed by running standard configuration for WES data (bin size of 250kb through -b 250kb of count-reads, and the allele counts for germline heterozygous SNPs have been selected between 30 and 400 through -c 30 -C 400 of count-alleles as the average coverage is 180x).
Requirements and set up¶
The demo requires that HATCHet has been successfully compiled and all the dependencies are available and functional. As such, the demo requires the user to properly set up the following paths:
PY="python3" # This is the full path to the version of PYTHON3 which contains the required `hatchet` module. When this corresponds to the standard version, the user can keep the given value of `python3`
:<<'```shell' # Ignore this line
The following paths are consequently obtained to point to the required components of HATCHet
CLUSTERBINS="${PY} -m hatchet cluster-bins"
PLOTBINS="${PY} -m hatchet plot-bins"
INFER="${PY} -m hatchet compute-cn"
PLOTCN="${PY} -m hatchet plot-cn"
:<<'```shell' # Ignore this line
We also ask the demo to terminate in case of errors and to print a trace of the execution by the following commands
set -e
set -o xtrace
PS4='[\t]'
:<<'```shell' # Ignore this line
Global clustering¶
The first main step of the demo performs the global clustering of HATCHet where genomic bins which have the same copy-number state in every tumor clone are clustered correspondingly. To do this, we use cluster-bins, i.e. the HATCHet’s component designed for this purpose. At first, we attempt to run the clustering using the default values of the parameters as follows:
${CLUSTERBINS} demo-wes.bb -o demo-wes.seg -O demo-wes.bbc -e 12 -tB 0.03 -tR 0.15 -d 0.08
:<<'```shell' # Ignore this line
For different type of data it is essential to assess the quality of the clustering because this is performed by a Dirichlet process and it is affected by varying degrees of noise. This assesment is particularly important in the case of WES data where the variance is higher than expected, especially for RDR; in fact we often observe that the clusters are much wider in terms of RDR (x-axis) and tend to have a disc shape rather than the expected oval shape. To do this, we use plot-bins, i.e. the HATCHet’s component designed for the analysis of the data, and produce the cluster plot using the CBB command. To help we use the following options:
--xmin 0and--xmax 2allow to zoom in and to focus the figure on the same RDR (y-axis) range for every sample.-tS 0.005asks to plot only the clusters which cover at least the0.5%of the genome. This is useful to clean the figure and focus on the main components. To trace all steps, we also move the figure totR015-cbb.pdf.
${PLOTBINS} -c CBB demo-wes.bbc --ymin 0 --ymax 2 -tS 0.005
mv bb_clustered.png tR015-cbb.png
:<<'```shell' # Ignore this line
We thus obtain the following clustering:
We can easily notice that the clustering is not ideal and is clearly overfitting the data by choosing too many distinct clusters; in fact we notice the presence of many different clusters that are extremely close and have identical BAF in every sample. For example, orange/light blue/light orange clusters and purple/red clusters exhibit a very typical pattern of “striped” clusters which are always adjacent clusters which appear to be part of a wider cluster. A good condition to assess the quality of the clustering is to assess that every pair of clusters is clearly distinct in one of the two dimensions (RDR and BAF) in at least one sample.
Since Dirichlet clustering is not ad-hoc for this application, it can often result in overclustering. For this reason, cluster-bins additionally provides a procedure to merge clusters which are very likely to be part of a single cluster. However this procedure requires two maximum thresholds for doing this, one is the maximum shift for RDR (-tR 0.15) and one is the maximum shift for BAF (-tB 0.03). The default values allow to work with most of the datasets, however datasets of high variance, e.g. in the case of WES data, require to tune these parameters. In our example as in most WES datasets, BAF is pretty well estimated and the clusters exhibit small variance on the y-axis, accordingly, the default value -tB 0.03 is therefore good. Instead, RDR appears to have much higher variance; in fact, the clusters that are always adjacent span much more than 0.15 of RDR in the x-axis. Therefore, by looking at the plot, we can see that a value of -tR 0.5 fit much better the noise of RDR in our data and we repeat the clustering with this value.
${CLUSTERBINS} demo-wes.bb -o demo-wes.seg -O demo-wes.bbc -e 12 -tB 0.03 -tR 0.5 -d 0.08
:<<'```shell' # Ignore this line
We assess again the clustering using plot-bins as before.
${PLOTBINS} -c CBB demo-wes.bbc --ymin 0 --ymax 2 -tS 0.005
mv bb_clustered.png cbb.png
:<<'```shell' # Ignore this line
We thus obtain the following clustering:
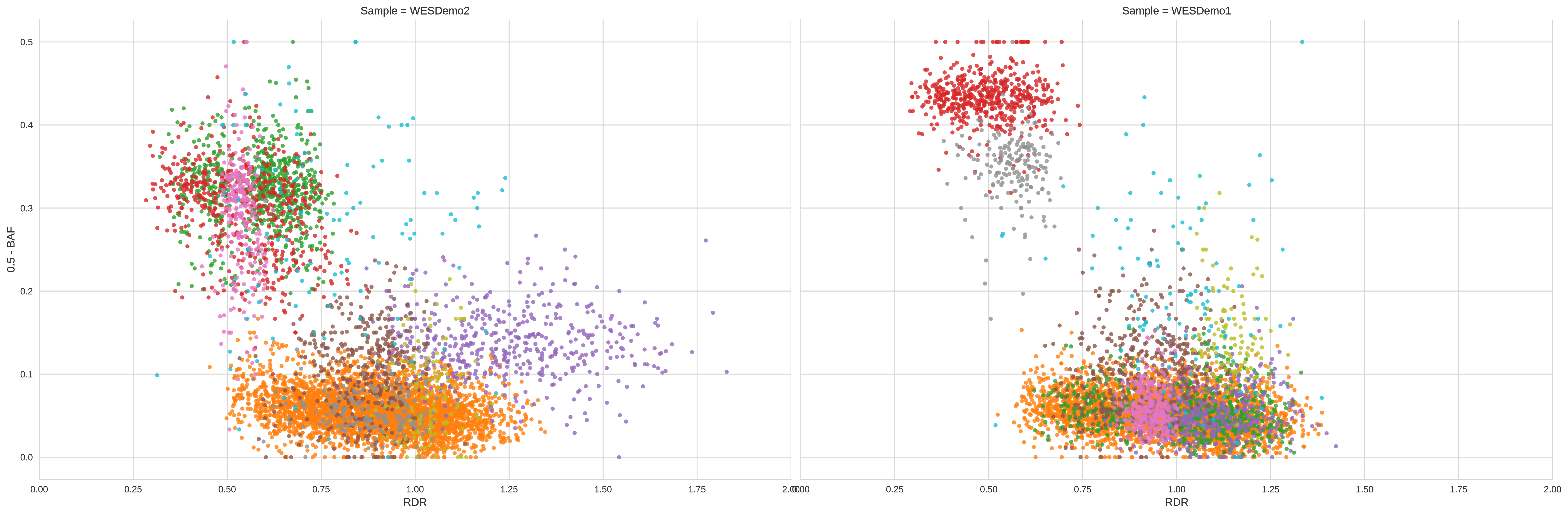
In this clustering the previously-described condition is met and all the different clusters are clearly distinct in at least one sample.
hatchet’s step¶
In the last step we apply hatchet, i.e. the component of HATCHet which estimates fractional copy numbers, infers allele-and-clone specific copy numbers, and jointly predicts the number of clones (including the normal clone) and the presence of a WGD.
We apply the last step with default parameters and, for simplicity of this demo, we apply only few changes:
As the dataset has high variance and noise (see clustering), we consider a minimum clone proportion
-uslightly higher than the default value, i.e.6%. We do this because we cannot infer tumor clones with very low proportions when there is high noise and because potential clones inferred with very low proportions may simply be the result of overfitting. In fact, when using values of-usmaller than6%we obtain solutions with clone proporions identical to the minimum value of-u; this is the recommended criterion to determine the need of increasing the value of-u. Interestingly, we can observe the same overfitting sign when we consider too high values of the minimum clone proportion, for example-u 0.1. This happens because the value is too high to fit the given data. As such, it is always important to choose the minimum value which provides “non-overfitting” results, i.e. results where the clone proportions are not identical to the minimum. When this is not possible, as in very noisy datasets, we reccommend to either tune the clustering or keeping very low values of the minimum clone proportion, as HATCHet is still able to recover the main clonal composition even in the presence of mninor overfitting.We limit the number of clones to 6 for simplicity of this demo and because it is a reasonable value for CNAs when consider only few samples from the same patient.
We only consider 100 restarts for the coordinate-descent method; these are the number of attempts to find the best solution. This number is sufficient in this small example but we reccommend to use at least 400 restarts in standard runs.
${INFER} -i demo-wes -n2,6 -p 100 -v 2 -u 0.06 -r 12 -eD 6 -eT 12 -l 0.5 |& tee hatchet.log
:<<'```shell' # Ignore this line
We obtain the following summary of results:
## Scores approximating second derivative for diploid results
## Diploid with 2 clones - OBJ: 25.198649 - score: -0.0948974010472
## Diploid with 3 clones - OBJ: 15.247768 - score: -0.093570025792
## Diploid with 4 clones - OBJ: 7.79973 - score: 0.183873549872
## Diploid with 5 clones - OBJ: 5.42398 - score: 0.071621041522
## Diploid with 6 clones - OBJ: 4.16034 - score: -0.0670271645544
## Scores approximating second derivative for tetraploid results
## Tetraploid with 2 clones - OBJ: 54.70041 - score: -0.258478300254
## Tetraploid with 3 clones - OBJ: 24.151418 - score: 0.0574235848181
## Tetraploid with 4 clones - OBJ: 13.46257 - score: 0.208505877387
## Tetraploid with 5 clones - OBJ: 10.311379 - score: 0.0136705311613
## Tetraploid with 6 clones - OBJ: 8.038751 - score: -0.0795999933666
# The chosen diploid solution has 4 clones with OBJ: 7.79973 and score: 0.183873549872
## The related-diploid resulting files are copied to ./chosen.diploid.bbc.ucn and ./chosen.diploid.seg.ucn
# The chosen tetraploid solution has 4 clones with OBJ: 13.46257 and score: 0.208505877387
## The related-tetraploid resulting files are copied to ./chosen.tetraploid.bbc.ucn and ./chosen.tetraploid.seg.ucn
# The chosen solution is diploid with 4 clones and is written in ./best.bbc.ucn and ./best.seg.ucn
HATCHet predicts the presence of 4 clones in the 3 tumor samples with no WGD and, especially, predicts that each sample contains two distinct tumor clones while sharing one of this. As there are inferred tumor clones with small clone proportions, there are only 2 samples, and the objective function does not significantly decrease after the chosen number of clones, there is no need to investigate the results of HATCHet by increasing the sensitivity with lower values of -l. However, the user could investigate the results of HATCHet when considering a lower sensitivity to small CNAs by considering higher values of -l, e.g. -l 0.6 or -l 0.8; this choice would be indeed motivated by the high noise of the dataset.
Analyzing inferred results¶
Finally, we obtain useful plots to summarize and analyze the inferred results by using plot-cn, which is the last component of HATCHet. As WES data have fewer point covering the genome, we slightly change the resolution of the plots by asking to obtain genomic regions merging fewer genomic bins through -rC 10 -rG 1. As such, we run plot-cn as follows
${PLOTCN} best.bbc.ucn -rC 10 -rG 1
exit $?
First, plot-cn summarizes the values of tumor purity and tumor ploidy for every sample of the patient as follows:
### SAMPLE: WESDemo2 -- PURITY: 0.7534724 -- PLOIDY: 1.84640419971 -- CLASSIFICATION: DIPLOID
### SAMPLE: WESDemo1 -- PURITY: 0.9283579 -- PLOIDY: 1.90711595733 -- CLASSIFICATION: DIPLOID
Next, plot-cn produces some informative plots to evaluate the inferred results. Among all the plots, 3 of those are particularly important.
The first intratumor-clones-totalcn.pdf represents the total-copy numbers for all tumor clones in fixed-size regions (obtained by merging neighboring genomic bins).
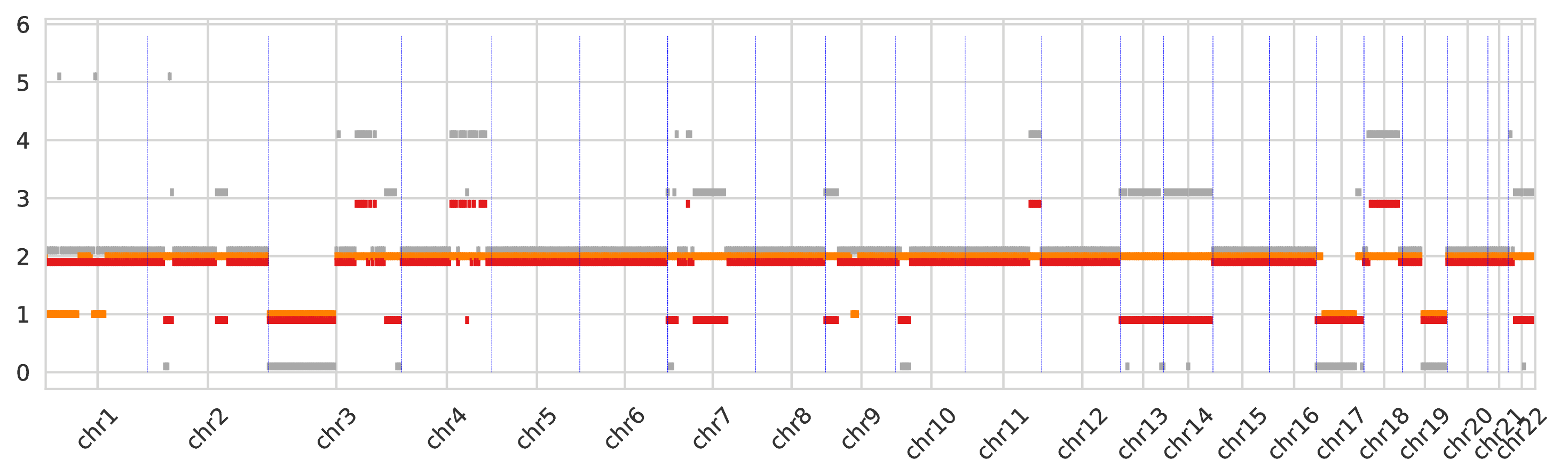 Every tumor clone is identified by a color and a dot is drawn for every genomic region (which are partitioned) for the corresponding total copy number.
Every tumor clone is identified by a color and a dot is drawn for every genomic region (which are partitioned) for the corresponding total copy number.
The second intratumor-clones-allelecn.pdf similarly represents the allele-specific copy numbers (split between the bottom and top regions of the figure) as the plot above.
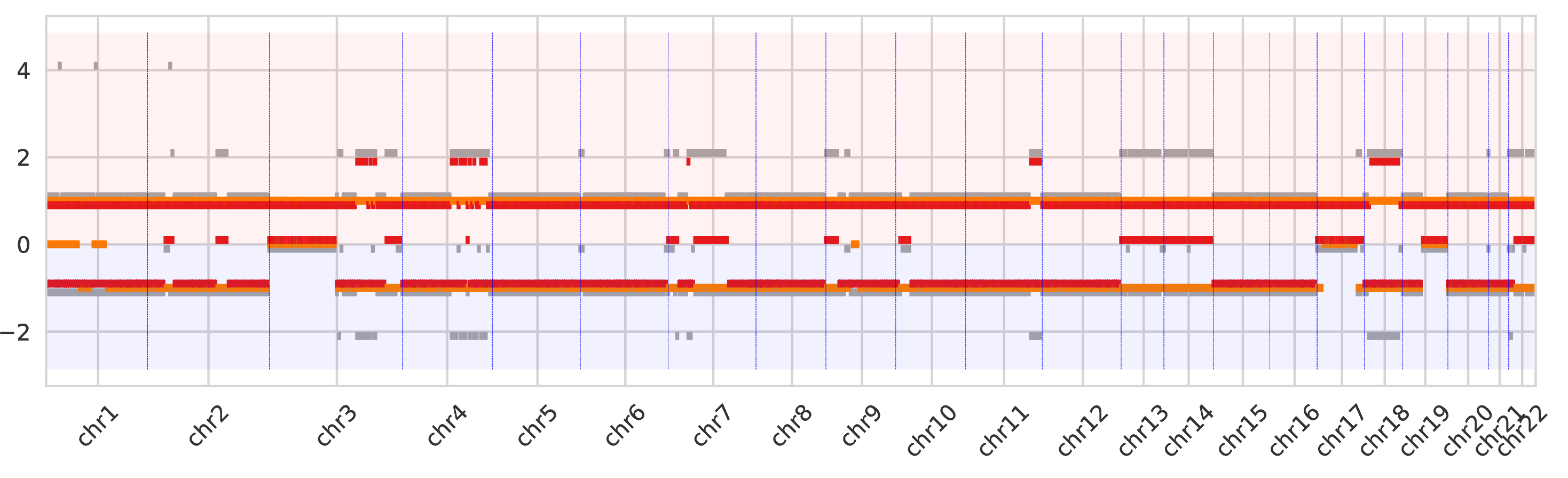
The third intratumor-profiles.pdf represents both the clone proportions and the total copy numbers of every clone in genomic regions.
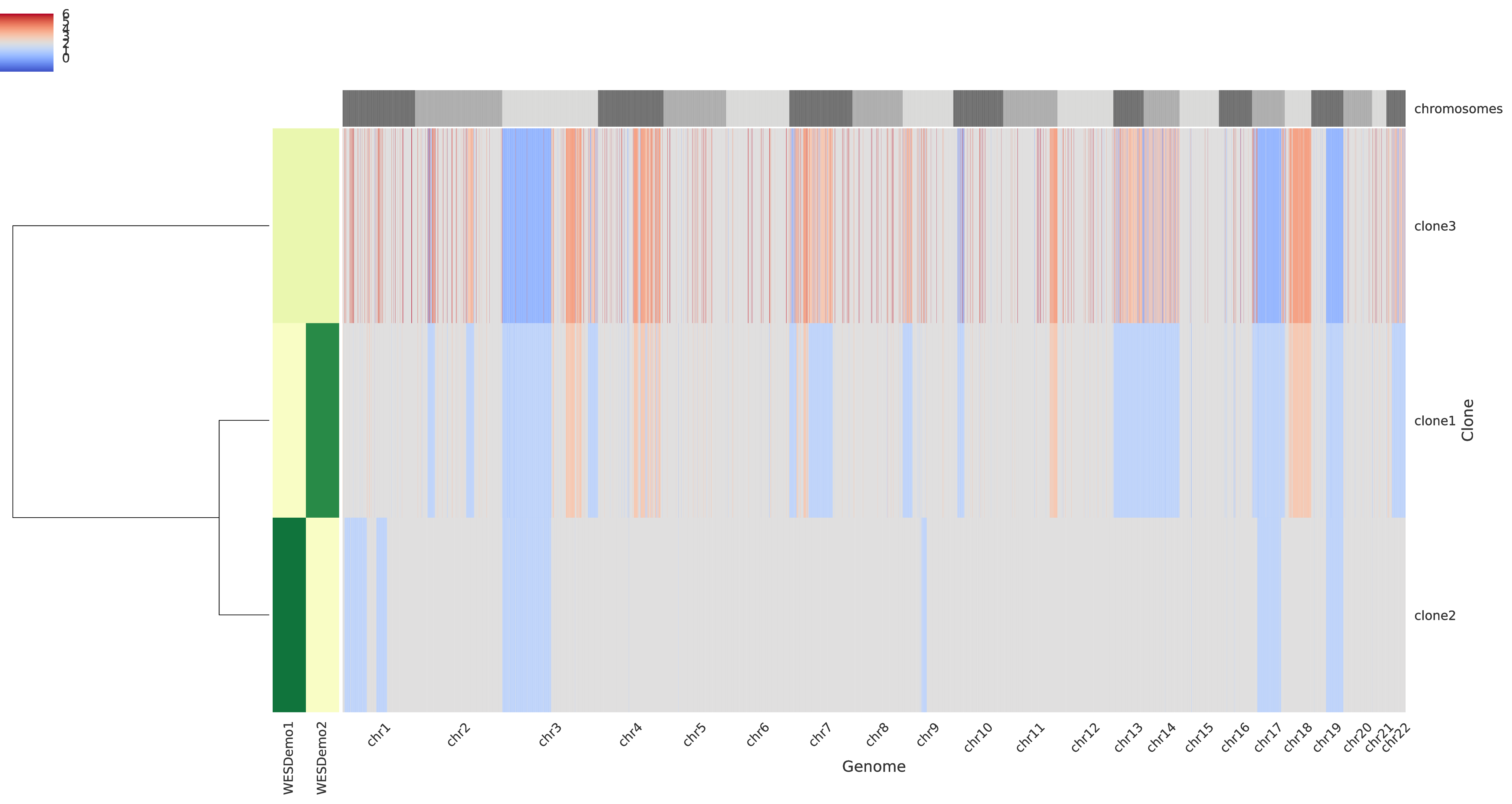 The main heatmap in the right side of the figure represent the total copy number of every clone (i.e. a row) for every genomic region (which are partition into chromosomes as described at the top of the heatmap) such that grey color indicate regions with base copy number not affected by CNAs (but they can be affected by a WGD when this occurrs), blue colors indicates deletions, and red colors indicate amplifications; in general, the stronger the color the smaller/higher the corresponding aberration. The smaller heatmap in the left side describes the clone proportion of each clone in each sample such that the lightest color correspond to absence while darker colors indicate higher clone proportions. Last, in the left-most part there is a dendogram which hierarchically clusters the tumor clones based on similiraity.
The main heatmap in the right side of the figure represent the total copy number of every clone (i.e. a row) for every genomic region (which are partition into chromosomes as described at the top of the heatmap) such that grey color indicate regions with base copy number not affected by CNAs (but they can be affected by a WGD when this occurrs), blue colors indicates deletions, and red colors indicate amplifications; in general, the stronger the color the smaller/higher the corresponding aberration. The smaller heatmap in the left side describes the clone proportion of each clone in each sample such that the lightest color correspond to absence while darker colors indicate higher clone proportions. Last, in the left-most part there is a dendogram which hierarchically clusters the tumor clones based on similiraity.